工业时序数据预测:Datalayers × TimesFM 2.5 端到端实践
概述
随着工业物联网、智能制造的深度推进,企业对数据驱动决策的需求迎来爆发式增长,时序预测已成为生产运维、能耗管理、供应链优化等核心场景的关键能力,企业用户将 “平台能否提供开箱即用的行业智能算法与模型” 作为时序数据平台选型的核心指标。 但在工业场景落地中,传统时序预测方案正面临多重难以突破的瓶颈:
但在工业场景落地中,传统时序预测方案正面临多重难以突破的瓶颈:
- 高频海量数据处理压力陡增:工业设备分钟级甚至亚秒级的振动、电流、压力、能耗等指标持续上传,数据维度与规模急剧膨胀,传统统计模型与机器学习方案的特征工程、模型维护成本指数级上升,极易出现异常漏报、预测误报。
- 预测精度与前瞻性要求严苛:非计划停机带来的巨大损失、双碳目标下的能耗刚性约束,都对预测的精准度、长周期预测能力提出了极高要求。
- 异构数据适配成本高:不同工厂、产线、设备的采样频率、字段规范、数据单位、缺失模式差异极大,传统方案需要大量手工对齐、数据补齐与定制化特征工程,落地周期长、复用性差。
- 多场景模型运维复杂:预测性维护、负荷预测、备件需求、质量趋势等场景往往需要独立建模,形成庞大的模型群,运维成本高、迭代效率低,同时难以满足工业场景 “数据不出域” 的安全合规要求。
基于此,时序数据库 + 预训练时序大模型的组合方案,成为破解上述痛点的最优解之一。本文将详细介绍 Google Research 开源的 TimesFM 2.5 时序基础模型,与 Datalayers 时序数据库的深度融合方案,提供可直接复现的端到端落地实践,帮助企业快速搭建低成本、高可用、泛化能力强的时序预测体系。
TimesFM2.5 是 Google 于2025年9月发布的 TimesFM(Time Series Foundation Model)系列模型最新版本 。这是一种表现优秀的时序预测模型,且经过了预训练,部署与使用十分简单。在工业领域也有良好的发挥。
本文通过 Datalayers + TimesFM2.5 的结合,实现时序数据预测。
模型表现
以下是基于 Electricity Load Forecasting 数据集,使用 TimesFM2.5,模型 context 长度 10240,预测 horizon 48 的结果:
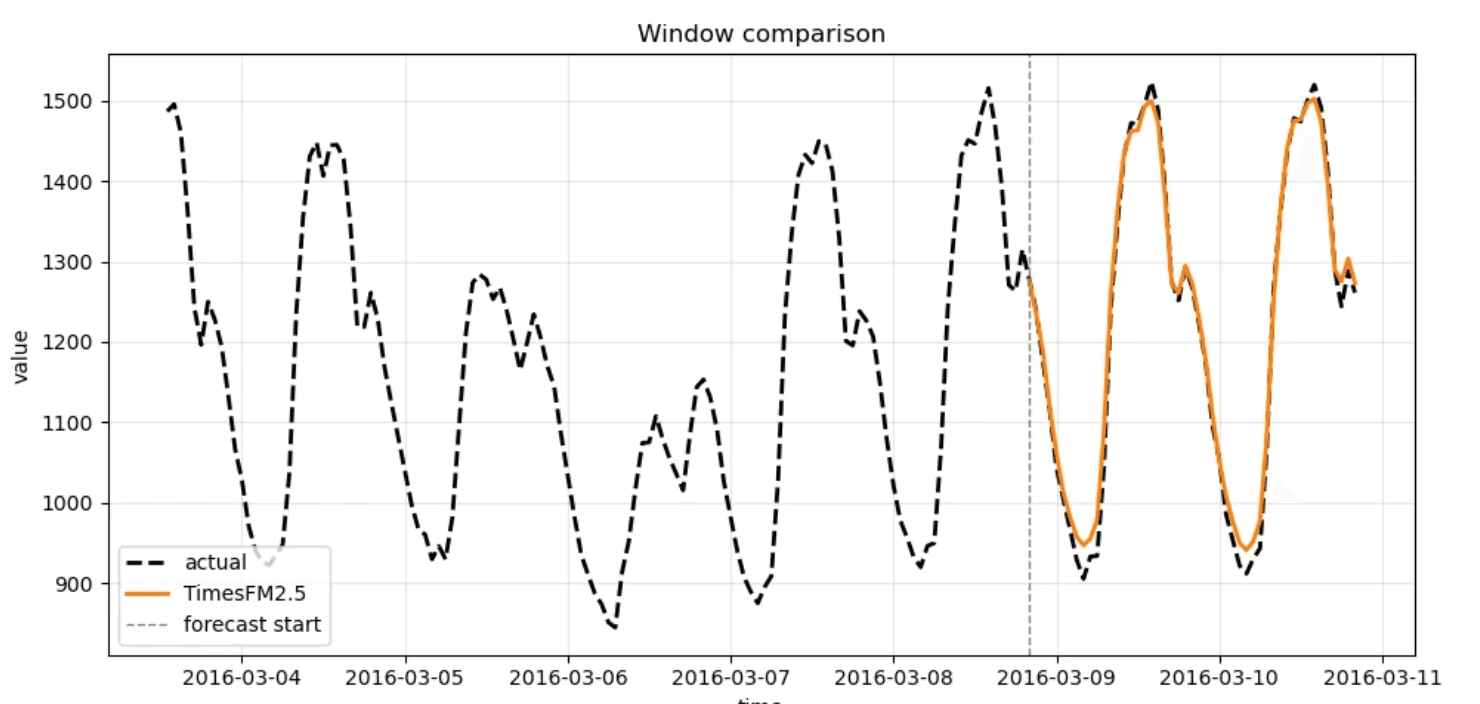
端到端实践
环境要求
- python >= 3.10
需要的依赖库
- flightsql-dbapi 0.2.2(用于连接Datalayers)
- pandas 2.3.3
- matplotlib 3.10.8
- kagglehub 1.0.0(用于获取数据集)
模型安装
具体安装步骤可以参考TimesFM ,本文给出 conda 虚拟环境,python=3.10的模型安装过程。
- 拉取模型源码
git clone https://github.com/google-research/timesfm.git
- 创建虚拟环境,并安装 TimesFM2.5
conda create -n tsforecast python=3.10 pip -y
conda activate tsforecast
pip install -e .[torch] # 本文以torch版本为例
TimesFM2.5 支持 covariate forecasting,使用前需要安装 xreg 相关的依赖。
模型使用示例
以下是官方提供的一个直线和正弦曲线预测简单示例:
import torch
import numpy as np
import timesfm
torch.set_float32_matmul_precision("high")
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained("google/timesfm-2.5-200m-pytorch")
model.compile(
timesfm.ForecastConfig(
max_context=1024,
max_horizon=256,
normalize_inputs=True,
use_continuous_quantile_head=True,
force_flip_invariance=True,
infer_is_positive=True,
fix_quantile_crossing=True,
)
)
point_forecast, quantile_forecast = model.forecast(
horizon=12,
inputs=[
np.linspace(0, 1, 100),
np.sin(np.linspace(0, 20, 67)),
], # Two dummy inputs
)
point_forecast.shape # (2, 12)
quantile_forecast.shape # (2, 12, 10): mean, then 10th to 90th quantiles.
forecast 是最常用的单变量预测入口,接收 horizon(预测窗口)和 inputs(预测的 batches 列表),返回形状(batch_size, horizon)的点预测 ndarray 和形状(batch_size, horizon, 10)的分位数预测 ndarray。具体 API Reference 可参考TimesFM
模型可以从 huggingface 下载或者使用本地模型权重,若使用本地模型权重,则需要将 from_pretrained 方法的模型id参数替换为本地模型权重所在目录,格式需要是 Unix 完全展开的路径格式(”~”和$开头的环境变量均无法解析)。
安装 Datalayers
此处使用 Docker 做为安装方式,更多安装方式见 Datalayers 文档。
docker run --name datalayers -d \
-p 8360:8360 -p 8361:8361 \
datalayers/datalayers:latest
数据准备
通过 dlsql 命令行工具在 Datalayers 中创建对应的 database 与 table, 如下:
> create database test
Query OK, 0 rows affected. (0.001 sec)
> use test
Database changed to `test`
test > -- 在 dlsql cli 中执行
CREATE TABLE test.electricity (
`datetime` TIMESTAMP(9) NOT NULL DEFAULT CURRENT_TIMESTAMP,
`Holiday_ID` INT32 NOT NULL,
`nat_demand` FLOAT32,
`T2M_toc` FLOAT32,
`QV2M_toc` FLOAT32,
`TQL_toc` FLOAT32,
`W2M_toc` FLOAT32,
`T2M_san` FLOAT32,
`QV2M_san` FLOAT32,
`TQL_san` FLOAT32,
`W2M_san` FLOAT32,
`T2M_dav` FLOAT32,
`QV2M_dav` FLOAT32,
`TQL_dav` FLOAT32,
`W2M_dav` FLOAT32,
`holiday` INT32,
`school` INT32,
TIMESTAMP KEY(`datetime`)
)
PARTITION BY HASH (`holiday`) PARTITIONS 1
ENGINE=TimeSeries
Query OK, 0 rows affected. (0.009 sec)
上述示例在 Datalayers 中创建了一个名为 test 的数据库,并创建了名为 electricity 的表,其中包含 nat_demand 的预测目标列。数据来源:Electricity Load Forecasting 。
然后通过导入脚本 tsforecast-demo ,将数据导入到 Datalayers 中。
模型验证
详细代码见tsforecast-demo。
根据上述代码仓库说明,即可实现相关时序数据预测的验证。
效果如下:
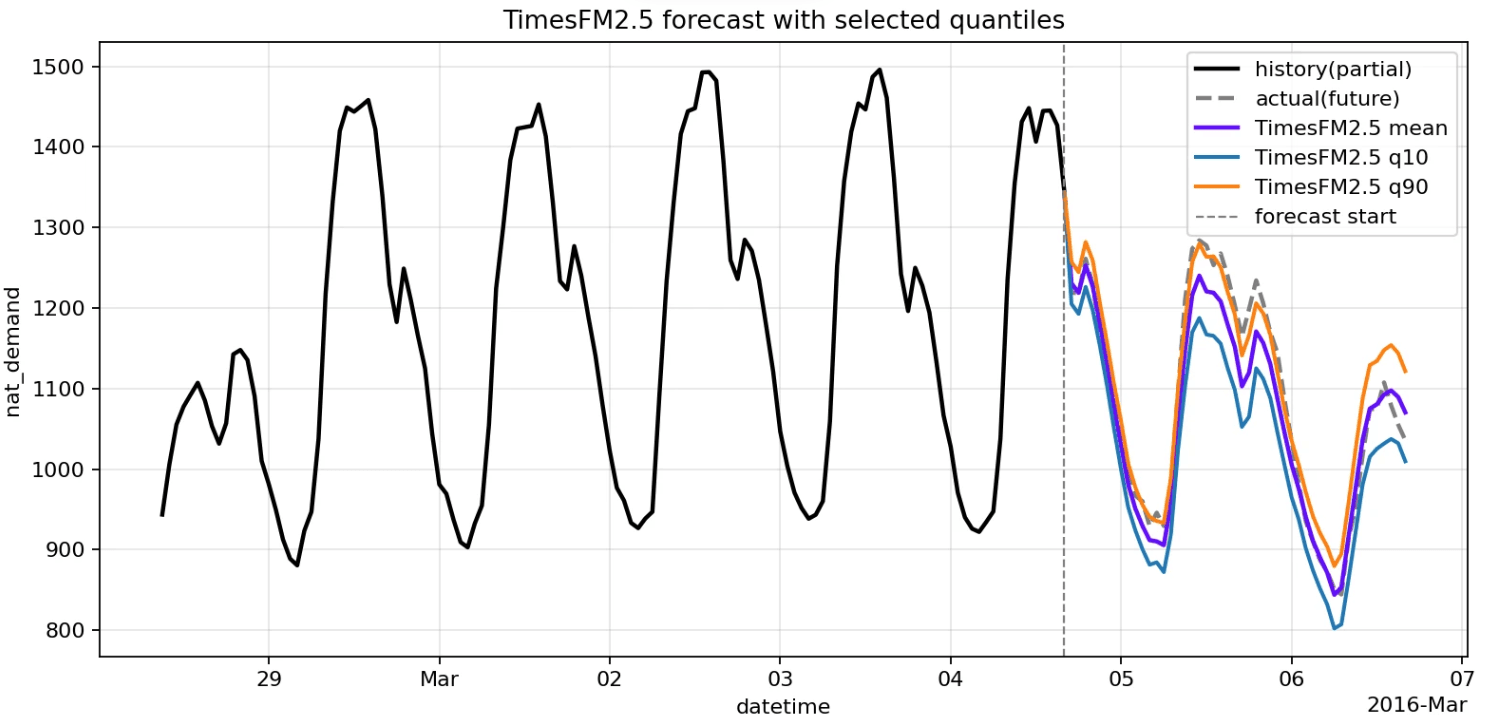
总结
以上模型使用和连接 Datalayers 示例已经足够完成 Datalayers + TimesFM2.5 的最小结合。生产环境可结合已有的 Datalayers 部署,将工程化的预测服务无侵入地与 Datalayers 结合,以进行原型验证。
本文所有代码位于 GitHub。
立即体验 Datalayers
高性能、云原生的时序数据存储引擎,轻松应对海量数据的写入与查询