AI 大模型与 Datalayers + MCP 的深度融合:开启数据分析智能新时代

引言
随着人工智能技术的发展,大语言模型(LLM)正在改变数据分析的人机交互方式。本文将介绍如何通过 Model Context Protocol(MCP)将 Datalayers 与 LLM 结合,实现自然语言驱动的数据查询与分析。
MCP简介
Model Context Protocol(MCP)是一种开放协议,用于在 LLM 应用与外部工具/数据源之间建立标准化交互。其目标是让模型在受控边界内调用工具、读取资源并完成可验证的任务执行。
MCP 架构遵循客户端-服务器模式,其中一个宿主应用程序可以连接到多个服务器:
- MCP宿主(Host): 如Claude Desktop、IDE或 AI 工具等需要使用 MCP 访问数据的程序
- MCP客户端(Client): 与服务器维持 1:1 连接的协议客户端
- MCP服务器(Server): 通过标准化的 Model Context Protocol 暴露特定功能的轻量级程序
MCP 为大语言模型提供了工具调用能力:LLM 可以调用预定义工具(如 SQL 查询、数据转换、图表生成),不再局限于静态训练知识,从而实现面向真实数据的分析与决策支持。
创建 MCP Server
Datalayers MCP Server 是连接 Datalayers 多模数据库与大语言模型的关键组件。它提供了一系列 API,允许 LLM 通过自然语言指令查询和分析 Datalayers 中存储的时序数据。
Datalayers MCP Server提供以下主要功能:
- 资源列表: 列出 Datalayers 数据库中的所有可用数据库
- 资源查询: 获取数据库架构信息,包括表结构和字段定义
- SQL执行: 执行用户通过自然语言描述的SQL查询并返回结果
- 结果格式化: 将查询结果格式化为易于理解和展示的形式
实现代码
以下是Datalayers MCP Server的 mcp_server.py 代码片段:
import asyncio
import logging
import os
import http.client
import json
from mcp.server import Server
from mcp.types import Resource, Tool, TextContent
from pydantic import AnyUrl
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("datalayers_mcp_server")
def get_db_config():
"""Get Datalayers database configuration from environment variables."""
config = {
"host": os.getenv("DATALAYERS_HOST", "127.0.0.1"),
"port": int(os.getenv("DATALAYERS_PORT", "8361")),
"username": os.getenv("DATALAYERS_USER", "admin"),
"password": os.getenv("DATALAYERS_PASSWORD", "public"),
"database": os.getenv("DATALAYERS_DATABASE", "neuronex")
}
if not all([config["username"], config["password"]]):
logger.warning("Database credentials not fully configured. Check environment variables.")
return config
def create_connection():
"""Create an HTTP connection to the Datalayers server."""
config = get_db_config()
conn = http.client.HTTPConnection(host=config["host"], port=config["port"])
return conn, config
def execute_query(query, conn=None, config=None):
"""Execute a SQL query against Datalayers database."""
if conn is None or config is None:
conn, config = create_connection()
# Encode credentials for Basic Auth
import base64
auth = base64.b64encode(f"{config['username']}:{config['password']}".encode()).decode()
url = f"/api/v1/sql"
headers = {
"Content-Type": "application/binary",
"Authorization": f"Basic {auth}"
}
try:
conn.request(method="POST", url=url, headers=headers, body=query)
response = conn.getresponse()
status = response.status
if status != 200:
error_msg = response.read().decode('utf-8')
logger.error(f"Query failed with status {status}: {error_msg}")
return {"success": False, "error": error_msg}
# Parse the response
result = response.read().decode('utf-8')
try:
# Try to parse as JSON
parsed_result = json.loads(result)
return {"success": True, "data": parsed_result}
except json.JSONDecodeError:
# If not JSON, return as text
return {"success": True, "data": result}
except Exception as e:
logger.error(f"Error executing query: {str(e)}")
return {"success": False, "error": str(e)}
# Initialize the MCP server
app = Server("datalayers_mcp_server")
@app.list_resources()
async def list_resources() -> list[Resource]:
"""List available resources in the Datalayers database."""
logger.info("Listing resources")
conn, config = create_connection()
# Query to list databases
databases_query = "SHOW DATABASES;"
databases_result = execute_query(databases_query, conn, config)
resources = []
if databases_result["success"]:
try:
# Add each database as a resource
if isinstance(databases_result["data"], list):
for db in databases_result["data"]:
if isinstance(db, dict) and "Database" in db:
db_name = db["Database"]
resources.append(Resource(
uri=f"datalayers://{db_name}",
name=db_name,
description=f"Datalayers database: {db_name}"
))
except Exception as e:
logger.error(f"Error parsing database list: {str(e)}")
return resources
@app.read_resource()
async def read_resource(uri: AnyUrl) -> str:
"""Read schema information for a Datalayers database resource."""
logger.info(f"Reading resource: {uri}")
# Parse the URI to extract database name
# Format: datalayers://database_name
parts = str(uri).split("://")
if len(parts) != 2 or parts[0] != "datalayers":
return "Invalid Datalayers URI format. Expected: datalayers://database_name"
database = parts[1]
conn, config = create_connection()
# Query to list tables in the database
tables_query = f"SHOW TABLES FROM {database};"
tables_result = execute_query(tables_query, conn, config)
if not tables_result["success"]:
return f"Error reading database {database}: {tables_result.get('error', 'Unknown error')}"
# Format the result as a readable string
result = f"Database: {database}\n\nTables:\n"
try:
if isinstance(tables_result["data"], list):
for table_info in tables_result["data"]:
table_name = list(table_info.values())[0] if isinstance(table_info, dict) else str(table_info)
result += f"- {table_name}\n"
# Get schema for each table
schema_query = f"DESCRIBE {database}.{table_name};"
schema_result = execute_query(schema_query, conn, config)
if schema_result["success"] and isinstance(schema_result["data"], list):
result += " Columns:\n"
for column in schema_result["data"]:
if isinstance(column, dict):
col_name = column.get("Field", "Unknown")
col_type = column.get("Type", "Unknown")
result += f" - {col_name} ({col_type})\n"
except Exception as e:
logger.error(f"Error formatting database info: {str(e)}")
result += f"\nError retrieving complete information: {str(e)}"
return result
@app.list_tools()
async def list_tools() -> list[Tool]:
"""List available tools for interacting with Datalayers."""
logger.info("Listing tools...")
return [
Tool(
name="execute_sql",
description="Execute an SQL query on the TimeSeries database Datalayers",
inputSchema={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The SQL query to execute"
}
},
"required": ["query"]
}
)
]
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
"""Call a tool to interact with the Datalayers database."""
logger.info(f"Calling tool: {name} with arguments: {arguments}")
if name != "execute_sql":
raise ValueError(f"Unknown tool: {name}")
query = arguments.get("query")
if not query:
raise ValueError("Query is required")
# Execute the query
result = execute_query(query)
if not result["success"]:
logger.error(f"Error executing SQL '{query}': {result.get('error', 'Unknown error')}")
return [TextContent(type="text", text=f"Error executing query: {result.get('error', 'Unknown error')}")]
# Format the result
try:
if isinstance(result["data"], dict):
return [TextContent(type="text", text=json.dumps(result["data"], indent=2))]
elif isinstance(result["data"], list):
formatted_result = ""
# Check if the list contains dictionaries (rows with column names)
if result["data"] and isinstance(result["data"][0], dict):
# Get column names from the first row
columns = list(result["data"][0].keys())
formatted_result += " | ".join(columns) + "\n"
formatted_result += "-" * (sum(len(col) for col in columns) + 3 * (len(columns) - 1)) + "\n"
# Add each row
for row in result["data"]:
formatted_result += " | ".join(str(row.get(col, "")) for col in columns) + "\n"
else:
# Simple list output
for item in result["data"]:
formatted_result += str(item) + "\n"
return [TextContent(type="text", text=formatted_result)]
else:
# String or other type
return [TextContent(type="text", text=str(result["data"]))]
except Exception as e:
logger.error(f"Error formatting query result: {str(e)}")
return [TextContent(type="text", text=f"Error formatting result: {str(e)}")]
async def main():
"""Main entry point to run the MCP server."""
from mcp.server.stdio import stdio_server
logger.info("Starting Datalayers MCP server...")
config = get_db_config()
logger.info(f"Database config: {config['host']}:{config['port']} as {config['username']}")
# Test database connection
conn, _ = create_connection()
test_result = execute_query("SELECT 1;", conn)
if test_result["success"]:
logger.info("Successfully connected to Datalayers database")
else:
logger.warning(f"Failed to connect to Datalayers database: {test_result.get('error', 'Unknown error')}")
async with stdio_server() as (read_stream, write_stream):
try:
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
except Exception as e:
logger.error(f"Server error: {str(e)}", exc_info=True)
raise
if __name__ == "__main__":
asyncio.run(main())
基于Cursor部署 Datalayers MCP Server
Cursor 是一款强大的AI辅助编码 IDE,集成了大语言模型能力,可以帮助开发者更高效地编写和调试代码。利用 Cursor 的 MCP 插件系统,我们可以轻松部署 Datalayers MCP Server,为 AI 编码助手提供访问 Datalayers 数据库的能力,快速进行数据分析与探索。
环境准备
首先,确保 Cursor 使用的 Python 解释器已安装必要依赖;如缺少基础库,请先完成安装。
pip install mcp>=1.3.0
pip install pydantic>=2.8.2
Cursor集成
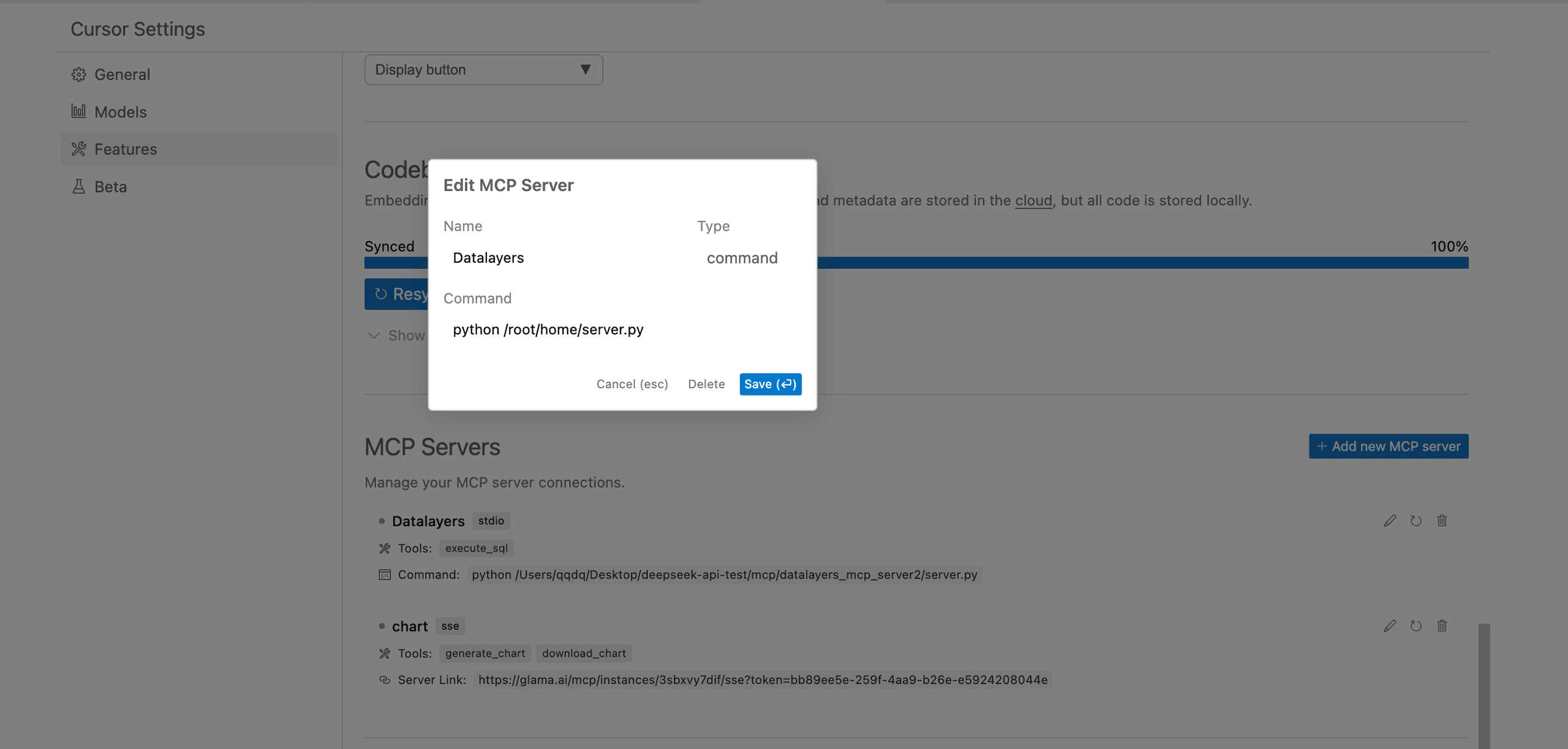
在 Cursor IDE → Cursor Settings → Features → MCP Servers 中,通过 MCP 扩展面板添加本地 MCP 服务器:
- Name: Datalayers
- Type: command
- Command: python /{你的文件路径}/mcp_server.py
验证部署
部署完成后,可以通过 Cursor 的界面查看到 MCP 服务器的状态,包括当前 Datalayers MCP Server 内含的Tools:

部署 Datalayers 与准备数据
在开始使用 MCP 与 Datalayers 进行交互之前,我们需要确保 Datalayers 数据库正确部署并准备好测试数据。
Datalayers部署
部署步骤如下:
- 安装 Datalayers(Docker 方式)
docker run --name datalayers -d \ -v ~/dl_data:/var/lib/datalayers \ -p 8360:8360 -p 8361:8361 \ datalayers/datalayers:nightly - 准备测试数据
为了演示 LLM 结合 MCP 后的数据分析能力,我们需要准备一些测试数据。以下通过进入 Datalayers docker 命令行,进行创建库、建表以及写入数据
### 创建数据库 neuronex
create database neuronex
### 创建数据表 neuron_float
CREATE TABLE `neuron_float` (
`time` TIMESTAMP(3) NOT NULL,
`node_name` STRING NOT NULL,
`group_name` STRING NOT NULL,
`tag` STRING NOT NULL,
`value` DOUBLE,
timestamp key(time)
)
PARTITION BY HASH (node_name, group_name, tag) PARTITIONS 1
ENGINE=TimeSeries
with (ttl='7d')
### 插入数据
INSERT INTO neuron_float (time,node_name,group_name,tag,value) VALUES (now(),'m2','group2','tag88',555.8)
INSERT INTO neuron_float (time,node_name,group_name,tag,value) VALUES (now() - interval 0.5 hour,'m2','group2','tag88',123.8)
INSERT INTO neuron_float (time,node_name,group_name,tag,value) VALUES (now() - interval 3.5 hour,'m2','group2','tag88',456.8)
### 插入数据省略..
自然语言交互挖掘数据价值
有了 Datalayers MCP Server 和测试数据,我们现在可以展示如何通过自然语言交互挖掘数据价值。
数据探索用例测试
我们在 Cursor 中选择支持 MCP 的 Agent/Composer 模式,输入如下内容进行查询:
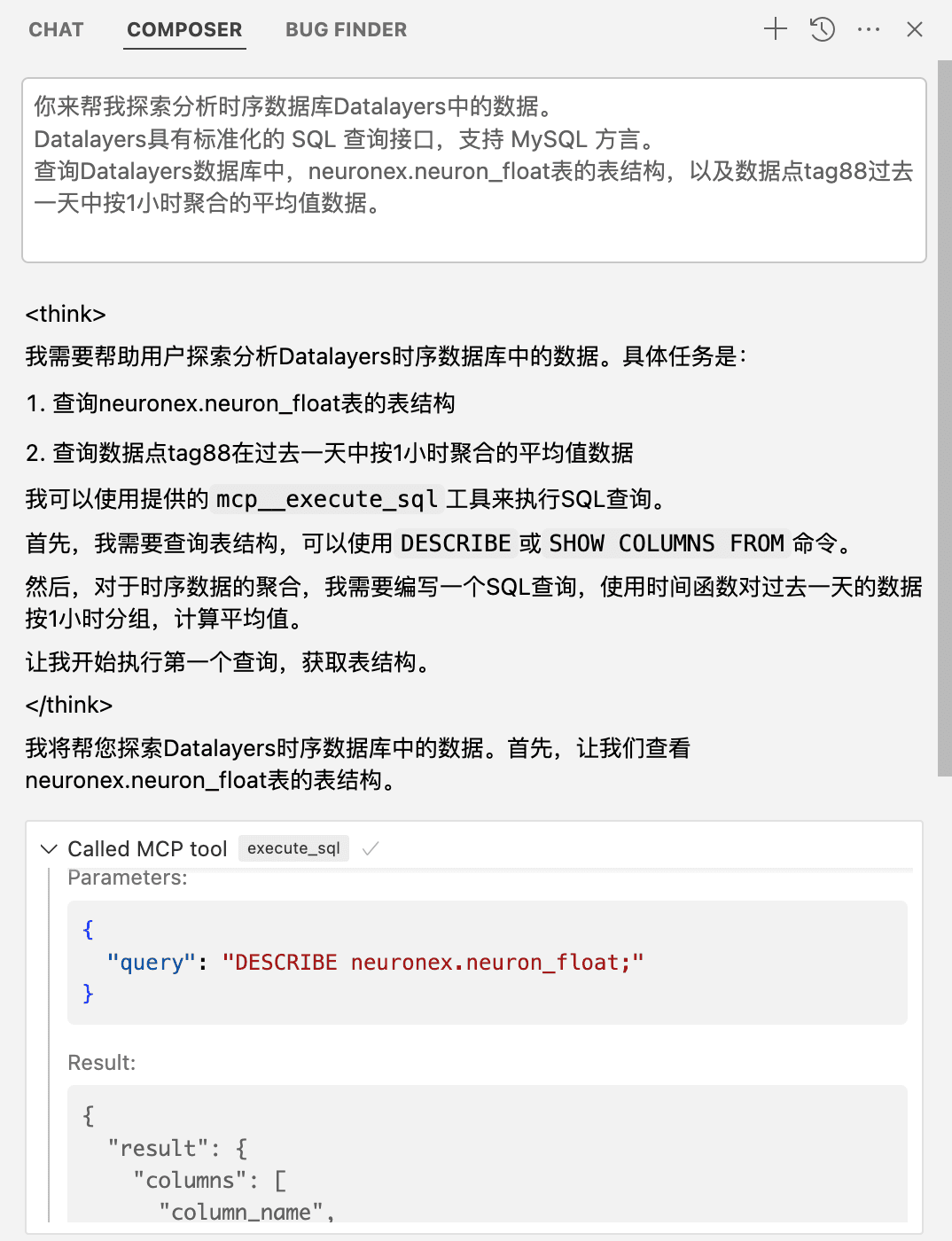
你来帮我探索分析时序数据库 Datalayers 中的数据。
Datalayers 使用 Datafusion 作为查询引擎,具有标准化的 SQL 语言,支持 MySQL 方言。
查询 Datalayers 数据库中,`neuronex.neuron_float` 表的表结构,以及数据点 tag88 过去一天中按1小时聚合的平均值数据。
以下是输出结果
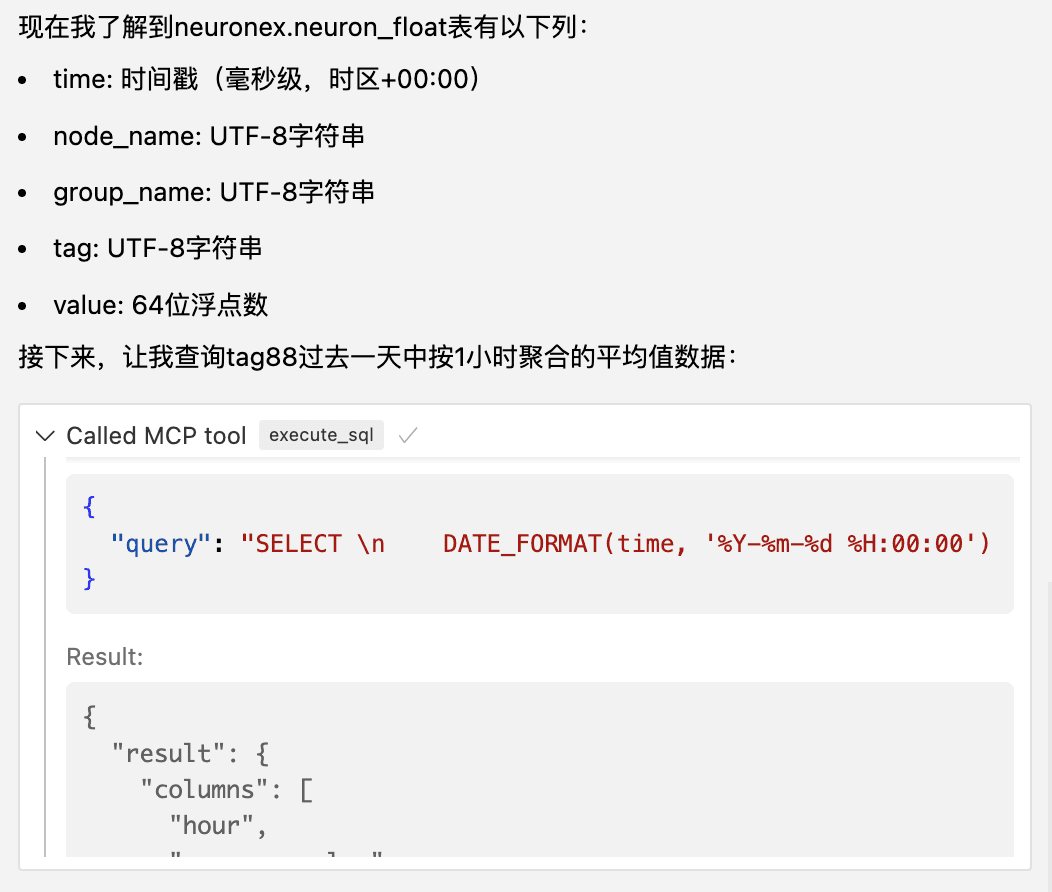

用户可以根据自身需求,对包括异常点检测、数据转换、数据统计分析等场景进行分析。
实践价值
通过 LLM、MCP 与 Datalayers 的结合,可快速实现以下收益:
降低分析门槛: 无需编写复杂 SQL 或掌握数据分析技能,通过自然语言即可进行复杂查询 加速洞察发现: AI 可以自动分析数据模式、趋势和异常,帮助快速发现问题和机会 持续交互式探索: LLM 利用 MCP 的能力,可以自主多轮调用 MCP,即使出现错误也会自动修复 知识累积: 系统可以记忆用户的分析历史,累积领域知识,提供更个性化的建议
结 语
Datalayers 与 MCP 的结合,通过大语言模型的智能增强,为时序数据分析带来了革命性的变化。用户可以摆脱编程和查询语言的限制,直接用自然语言与数据交流,极大地提高了数据价值挖掘的效率和可达性。
立即体验 Datalayers
高性能、云原生的时序数据存储引擎,轻松应对海量数据的写入与查询