ECP + Datalayers 实现链路追踪

链路追踪作为一种用于监控和观察分布式系统中请求流动和性能的技术,在现代微服务架构中扮演着重要角色。在复杂的分布式环境中,它可以记录并可视化跨多个服务与组件的完整请求路径,并提供每个服务节点上的执行时间,帮助开发人员清晰地掌握请求走向、识别性能瓶颈。
在出现故障或错误时,链路追踪能够提供详细的信息,帮助开发人员快速定位问题的根源,加速故障排查过程。通过分析链路追踪数据,团队可以基于实际使用情况优化服务、调整资源配置,从而进行容量规划和设计决策。
本文介绍 Datalayers 与 ECP 的集成方案,用于实现链路追踪数据的写入、检索与展示,辅助分布式系统监控和故障诊断。
产品介绍
Datalayers 是澜图未来(成都)数据科技有限公司开发的一款一款分布式多模态数据库,原生支持时序、全文检索、向量、键值等应用场景,以SQL为核心查询语言,兼容PromQL、Redis及InfluxDB行协议。面向可观测性、物联网(IoT/IIoT)、AI 等数据密集型场景,提供低延迟写入、低成本存储、高性能分析及云原生弹性部署能力,同时深度优化边缘环境适配性,满足各类边缘部署需求。
EMQX ECP:是一款面向工业 4.0 工业互联数据平台,能够满足工业场景大规模数据采集、处理和存储分析的需求,提供边缘服务的快速部署、远程操作和集中管理等功能,助力工业领域数据互联互通,以数据 + AI 驱动生产监测、控制和决策,实现智能化生产,提高效率、质量和可持续性。
链路追踪的实现
数据写入
EMQX ECP 相关的链路追踪服务 NeuronEX 和 EMQX 的 Trace 数据都支持通过 otlp protocol 写入到 otlp 协议的服务端,通过 OpenTelemetry Collector 的 otlp receivers 插件,可以开启 http 和 grpc 两种协议的接收器,OpenTelemetry Collector 收到 trace 数据后,通过各种 Exporter 插件可以将数据写入不同的后端数据库中。
由于 Datalayers 也支持 InfluxDB 行协议,可以通过 OpenTelemetry Collector 的 InfluxDB Exporter 插件与 Datalayers 实现集成。
如图所示,通过 OpenTelemetry Collector 将链路追踪数据存入 Datalayers:
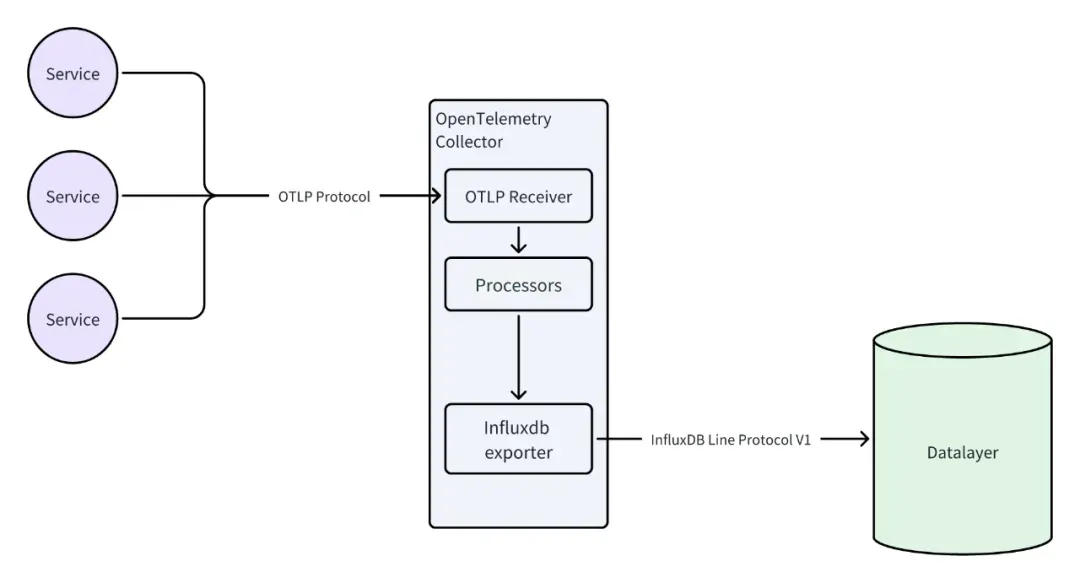
OpenTelemetry Collector 官方提供了 Core 和 Contrib 两个不同的版本。其中,前者只包基础的插件,后者包含了所有的插件。Core 版本中没有 influxdb exporter 插件,而 Contrib 版本中有。用户也可以按需自己构建镜像,只包含自己需要的插件,建议生产环境采用这种方式。
由于 Datalayers 仅支持 InfluxDB v1.x API 行协议, 因此需要在 OpenTelemetry Collector 的 InfluxDB Exporter 插件配置中开启 v1_compatibility 相关配置。
通过 span_dimensions 可以自定义行协议中的标签, 同时也是 Datalayers 表的联合索引字段,InfluxDB Exporter 默认强制 span_dimensions 会加上 trace_id 和 span_id,和我们自己配置的 span_dimensions 共同构成协议中的标签。
InfluxDB Exporter 所有配置详见:
最简 OpenTelemetry Collector 配置示例:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
exporters:
influxdb:
endpoint: http://172.31.104.77:8361
v1_compatibility:
enabled: true
db: demo
username: admin
password: public
service:
extensions: []
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [influxdb]
配置中 Exporter 的 endpoint 需要替换成自己的 Datalayers 地址。由于当前 Datalayers 默认只支持 v1 版本的 InfluxDB Line Protocol,所以需要将 v1_compatibility 设置为 true,要使用的数据库名称需要提前在 Datalayers 中创建。
在 receivers 中选择一个协议(比如 otlp),和协议对应的 endpoint 配置。从 receivers 中收到的数据会被 processor 处理,这里没有配置,所以直接发送到 exporters,即 Datalayers。当 Datalayers 收到数据后,会根据配置的数据库名称,将数据写入到对应的数据库中, 如果没有对应的表, 则会自动创建(如果关闭了 Datalayers 的自动创建表功能, 则需要提前在 Datalayers 中创建表)。
数据查询
Datalayers 使用 SQL 作为查询语言,语法清晰、上手成本低,便于快速构建查询与分析逻辑。
可以通过 REST API 或 Arrow Flight SQL 进行查询。其中,REST API 基于 HTTP;Arrow Flight SQL 基于 gRPC,通常具备更好的吞吐性能,并提供多语言 SDK。ECP 当前使用 REST API,后续可根据性能需求切换至 Arrow Flight SQL。
下图为 ECP 链路追踪查询界面:
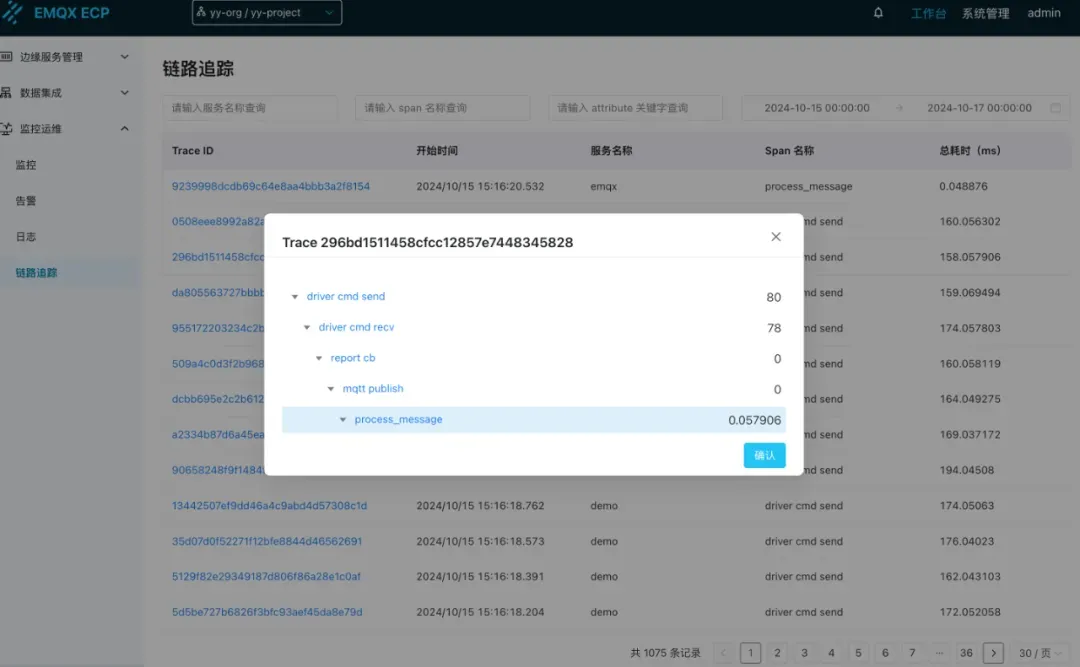
上图展示了 EMQX ECP 的链路追踪 trace_id 列表, 表格中列出了多个请求的追踪信息,包括它们的trace_id、开始时间、服务名称、Span 名称和总耗时。点开后还可以查阅每个 Trace 中所有的 Span, Span 之间的先后顺序, Span 的所有属性, 每个 Span 的耗时等等信息, 这些数据可以帮助开发者分析请求的处理效率,识别性能瓶颈,以及调试系统中的问题。
总结
本文完整介绍了 Datalayers 与 EMQX ECP 通过 OpenTelemetry Collector 的集成实践:将链路追踪数据以 InfluxDB 行协议写入 Datalayers,并通过 REST API 或 Arrow Flight SQL 完成查询与展示,实现对分布式系统的可观测性支持。
立即体验 Datalayers
高性能、云原生的时序数据存储引擎,轻松应对海量数据的写入与查询