Datalayers MCP Server: 轻松实现AI与数据分析协同

Datalayers 是高性能的分布式多模态数据库,提供时序、日志、向量、键值等多种数据模型,并支持基于 SQL 的统一查询与管理。借助分布式与存算分离架构,Datalayers 能在控制存储成本的同时稳定处理大规模数据。
MCP Server 是连接 AI 与数据的桥梁。MCP(Model Context Protocol)Server 是基于客户端-服务器架构的轻量级服务,用于为大型语言模型(LLM)提供与外部数据源、工具和服务的标准化连接。它将本地或远程资源(如文件、数据库、API)以工具(Tools)、资源(Resources)和提示模板(Prompts)的形式暴露给 LLM 应用(如 Claude、IDE 等)。
Datalayers MCP Server 是 Datalayers 的服务组件之一,通过 Streamable HTTP 提供对 Datalayers 数据的访问能力。该服务默认以只读方式(不允许写入、修改、删除)提供 SQL 查询接口,使大模型可以在受控边界内访问业务数据并完成分析。
注: Datalayers MCP Server 在 v2.2.15 正式发布,请使用 >= v2.2.15 的版本。
AI 与 Datalayers MCP Server 协同
本示例使用 Cursor 来连接 Datalayers MCP Server,通过获取 Datalayers 中存储的数据来实现业务数据的分析与诊断。相关操作步骤如下:
安装与配置
首先需要安装 Datalayers,并进行相应的配置。可以参考官方文档 Datalayers 文档 完成安装与配置。同时,还需要对 Cursor 进行配置,将大模型对话界面调整为 Agent 模型以开启 MCP 功能。 这里我们在本地部署了 Datalayers,MCP 配置如下:
{
"mcpServers": {
"Datalayers": {
"url": "http://localhost:8361/sse"
}
}
}
连接成功后会显示绿灯,如下所示:
构造数据
为验证异常检测流程的有效性,我们通过经典的 TSBS cpu_info 表模拟数据场景,可通过以下 Python 脚本生成测试数据:
import random
import numpy as np
from datetime import datetime, timedelta
def generate_cpu_records(host_id=99, hours=24, interval_sec=30):
host_tags = {
"hostname": f"host_{host_id}",
"region": "ap-southeast-1",
"datacenter": "ap-southeast-1-c",
"rack": "R23",
"os": "Ubuntu22.04",
"arch": "x86_64",
"team": "LN",
"service": "database-node",
"service_version": "3",
"service_environment": "production",
}
# 时间序列配置
start_time = datetime(2025, 3, 17)
current_time = start_time
total_records = int(hours * 3600 / interval_sec)
# 正常基准值
base_load = {"user": 30, "system": 15, "iowait": 3}
COLUMNS = [
"ts", # 时间戳
"hostname", # 主机名
"region", # 区域
"datacenter", # 数据中心
"rack", # 机架位置
"os", # 操作系统
"arch", # CPU架构
"team", # 运维团队
"service", # 服务名称
"service_version", # 服务版本
"service_environment", # 环境类型
"usage_user", # 用户态CPU
"usage_system", # 系统态CPU
"usage_idle", # 空闲CPU
"usage_nice", # 优先级进程CPU
"usage_iowait", # IO等待
"usage_irq", # 硬中断
"usage_softirq", # 软中断
"usage_steal",
"usage_guest",
"usage_guest_nice",
]
for _ in range(total_records):
# 生成基础指标(带时间相关性)
usage_user = base_load["user"] + random.randint(-5, 5)
usage_system = base_load["system"] + random.randint(-3, 3)
usage_idle = 100 - (usage_user + usage_system)
# 注入点异常(5%概率)
if random.random() < 0.05:
usage_user = random.choice([150, -20])
usage_system = random.choice([80, -10])
# 周期性异常(每小时55分触发)
if current_time.minute >= 55:
usage_user = int(base_load["user"] * 2.5)
usage_system += 20
# 持续性异常(每天14:10-14:20)
if current_time.hour == 14 and 10 <= current_time.minute <= 20:
usage_iowait = random.randint(30, 50)
usage_steal = random.randint(15, 25)
else:
usage_iowait = random.randint(0, 5)
usage_steal = 0
# 构建行协议格式
data = f"""cpu,hostname={host_tags["hostname"]} rack="{host_tags["rack"]}",os="{host_tags["os"]}",arch="{host_tags["arch"]}",team="{host_tags["team"]}",service="{host_tags["service"]}",service_version="{host_tags["service_version"]}",service_environment="{host_tags["service_environment"]}",sage_user={max(0, usage_user)},usage_system={max(0, usage_system)},usage_idle={max(0, usage_idle)},usage_nice={random.randint(0, 5)},usage_iowait={usage_iowait},usage_irq={random.randint(0, 2)},usage_softirq={random.randint(0, 2)},usage_steal={usage_steal},usage_guest={random.randint(0, 1)},usage_guest_nice={random.randint(0, 1)} {int(current_time.timestamp() * 1e9)}"""
yield data
current_time += timedelta(seconds=interval_sec)
# 使用示例
if __name__ == "__main__":
with open("cpu_data", "w") as f:
# 生成数据
for idx, data in enumerate(generate_cpu_records()):
f.write(data + "\n")
运行该 Python 脚本后,会得到一个 cpu_data 的数据文件。
数据导入
在导入前需先创建数据库,操作如下:
$ dlsql -u admin -p public -P 8360
Welcome to the DataLayers.
> create database demo
+---------------+
| affected_rows |
+---------------+
| 0 |
+---------------+
1 row in set (0.019 sec)
然后使用 Shell 命令通过行协议将生成的数据写入Datalayers中,如下:
curl -i -XPOST "http://127.0.0.1:8361/write?db=demo&u=admin&p=public&precision=ns" --data-binary @cpu_data
数据写成功后,我们即可使用大模型对数据进行分析与诊断。
使用大模型对数据进行分析与诊断
首先我们先让大模型查看一下数据库中有什么表以及表的 schema,验证大模型与 Datalayers 之间的通信,如下:
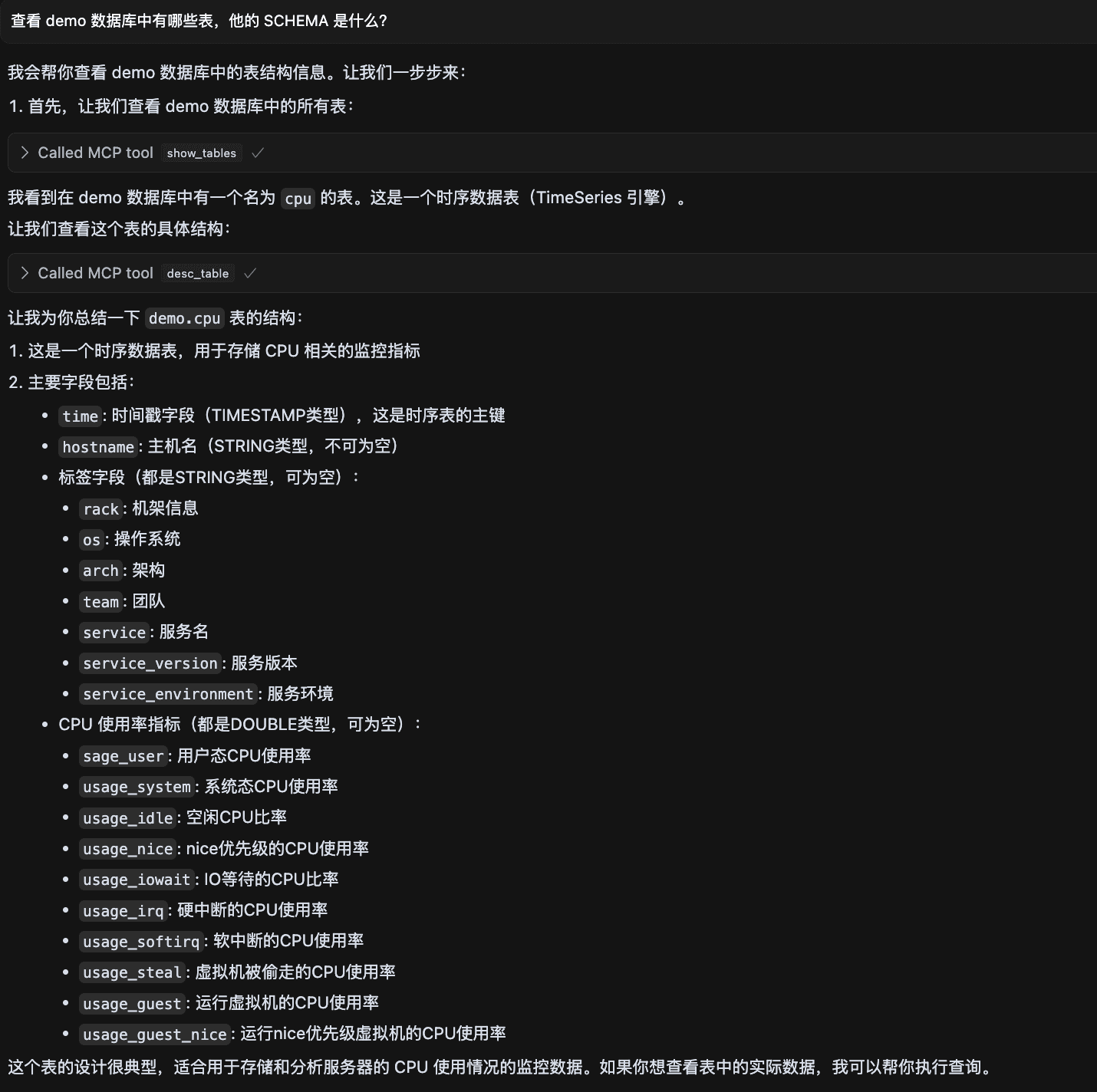
从上图可以看到,大模型已经成功获取并理解数据库中的表结构信息。其中,demo 库中的 cpu 表即为测试数据所在表。接下来可进一步让大模型查询数据并执行异常分析。

到此便完成了大模型通过 MCP 协议获取 Datalayers 中数据进行分析与诊断。
结语
Datalayers MCP Server 为 AI 与数据库协同提供了标准化接口。通过结合 Datalayers 的存储与查询能力、以及 MCP 的可控访问模型,团队可以更高效地构建自然语言驱动的数据分析流程。
立即体验 Datalayers
高性能、云原生的时序数据存储引擎,轻松应对海量数据的写入与查询